Introduction: The Short Answer for Skeptical Professionals
According to OpenAI’s official benchmarks and strategic positioning, ChatGPT 5.2 is a significant improvement over its predecessors for specific professional and “agentic” tasks like coding, data analysis, and creating business documents. The company presents data showing it is more accurate, more capable in complex workflows, and better at reasoning over long documents. However, this official narrative is met with considerable user skepticism, fueled by past experiences with model performance declining after launch and ongoing frustrations with the platform’s limitations.
This article cuts through the hype to provide a grounded analysis for entrepreneurs and business leaders. We will examine the key takeaways from the release, conduct a deep dive into OpenAI’s claims versus the reality reported by users, provide a practical playbook for extracting business value, honestly assess its persistent limitations, and answer the most pressing questions you might have.
Key Takeaways: The 5-Minute Briefing for Entrepreneurs
- It’s an Upgrade, Not a Revolution: GPT-5.2 is positioned as an incremental but powerful update focused on professional knowledge work, complex workflows, and “agentic” tasks, rather than a complete overhaul of the underlying technology (Source: OpenAI, TechCrunch).
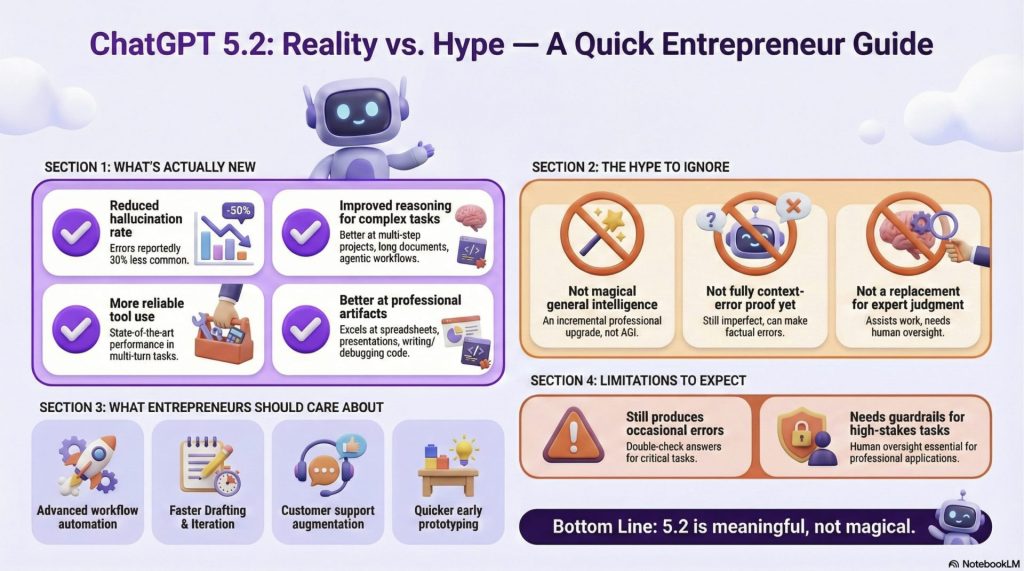
- Accuracy is Up, But Oversight is Still Mandatory: OpenAI claims GPT-5.2 “hallucinates less” and presents data showing fewer responses contain major errors, but the company explicitly warns the model is “imperfect” and requires human verification for critical tasks (Source: OpenAI Blog, OpenAI System Card).
- The improved capabilities come with a higher price tag, with a 40% increase in API token costs for the flagship GPT-5.2 model compared to GPT-5.1 (Source: OpenAI Blog, r/ChatGPT).
- The Focus is on ‘Agentic’ Workflows: The model is specifically designed to handle complex, multi-step projects that involve using tools, analyzing long documents, and performing data analysis, making it more of a workflow engine than a simple chatbot (Source: The Verge, OpenAI).
- User Trust is Low: Despite the official announcements and impressive benchmarks, many users express deep skepticism due to past experiences with models seemingly being downgraded after launch (the “bait and switch” concern), with some even reporting that the new model is worse for their specific use cases (Source: r/ChatGPT).
- It’s Still Highly Filtered: The sources indicate that GPT-5.2 comes with “more, even stronger guardrails” and that features like the long-requested “adult mode” are not expected until at least the first quarter of 2026, a key limitation for users in creative and other fields (Source: The Verge, r/ChatGPT).
The Full Analysis: Claims, Reality, and Your Bottom Line
What OpenAI Claims: The Official Story on GPT-5.2
OpenAI has positioned GPT-5.2 as its “most capable model series yet for professional knowledge work,” with a clear focus on unlocking tangible economic value for businesses (Source: OpenAI Blog). The official announcements highlight improvements across several key themes.
Enhanced Professional Task Performance
The central claim is that GPT-5.2 is substantially better at creating professional artifacts like spreadsheets, presentations, and other business documents. To back this up, OpenAI cites the GDPval benchmark, an evaluation measuring performance on knowledge work tasks across 44 different occupations. On this benchmark, GPT-5.2 Thinking “beats or ties top industry professionals on 70.9% of comparisons” (Source: OpenAI Blog). Crucially for business leaders, OpenAI also claims the model produced these outputs at “>11x the speed and <1% the cost of expert professionals,” suggesting a powerful ROI case when paired with human oversight (Source: OpenAI Blog).
Improved Factuality and Reduced Hallucinations
A major pain point for professional users has been the unreliability and “hallucinations” of previous models. OpenAI directly addresses this, stating that GPT-5.2 “hallucinates less” and that “responses with errors were 30%rel less common” in their internal testing (Source: The Verge, OpenAI Blog). The company’s own System Card provides specific data to substantiate this: when using a search tool, the rate of responses containing at least one major incorrect claim dropped from 8.8% for GPT-5.1 to 5.8% for GPT-5.2 (Source: OpenAI System Card). This claimed increase in dependability is a cornerstone of its pitch to enterprise clients.
Superior Coding and Development
For technical teams, OpenAI is touting state-of-the-art performance in software engineering. GPT-5.2 Thinking achieved a new top score of 55.6% on SWE-Bench Pro, a benchmark designed to test a model’s ability to solve realistic software engineering tasks across multiple programming languages (Source: OpenAI Blog). Early testers also report that the model is significantly stronger at front-end development and complex user interface work, making it a more powerful partner for engineers across the full stack (Source: OpenAI Blog).
Advanced Reasoning, Vision, and Long-Context
Beyond specific tasks, OpenAI claims foundational improvements in the model’s core cognitive abilities. It has set new state-of-the-art scores in long-context reasoning, allowing it to accurately analyze and synthesize information from documents containing hundreds of thousands of tokens (Source: OpenAI Blog). Its vision capabilities have also been upgraded, with error rates on chart reasoning and software interface understanding cut roughly in half. This means it can more accurately interpret dashboards, technical diagrams, and product screenshots. Finally, its ability to use external tools (“tool calling”) has been enhanced, enabling more reliable execution of complex, multi-step automated workflows (Source: OpenAI Blog).
Reality vs. Hype: A Grounded Look at the Release
While OpenAI’s claims are backed by extensive benchmarks, the release doesn’t exist in a vacuum. The context of the competitive landscape and the sentiment of the user base paint a more complex picture.
The “Code Red” Context
Multiple tech media outlets frame the GPT-5.2 launch as a direct response to intense competition, particularly from Google’s Gemini models (Source: TechCrunch, The Verge, CNBC). It was reported that OpenAI CEO Sam Altman issued an internal “code red” memo, calling on the company to marshal resources and focus on improving the core ChatGPT experience to reclaim its leadership position (Source: TechCrunch, CNBC). While OpenAI’s CEO of Applications, Fidji Simo, stated that the model has been in development for “many, many months,” Altman himself provided a timeline, telling CNBC he expects OpenAI to “exit its code red by January” (Source: The Verge, CNBC). This context suggests a highly reactive and competitive environment.
The User Trust Deficit
The most significant counterpoint to the official narrative comes from the user community itself. A thread on the r/ChatGPT subreddit reveals widespread skepticism and a deep-seated trust deficit. Many users pointed to a perceived “bait and switch” pattern where new models perform exceptionally well at launch only to be noticeably “scaled back” or degraded after a few weeks. This cycle is so familiar that users draw parallels to the predictable love/hate cycle of Microsoft Windows versions, like the beloved XP followed by the reviled Vista (Source: r/ChatGPT). This sentiment is potent, with some users immediately dismissing the new release. One user commented, “It’s actually hallucinating more, and the coding is worse,” while another, lamenting the unreliability of a previous version, stated, “I’ve never met a bigger liar than 5.1” (Source: r/ChatGPT). These comments directly contradict OpenAI’s primary claims and highlight the gap between benchmark performance and real-world user experience.
Incremental Gains or Marketing Spin?
The version number itself—5.2—has become a point of contention. Some users on Reddit performed a tongue-in-cheek calculation, suggesting that a jump from 5.1 to 5.2 represents only a “~2% better” model (Source: r/ChatGPT). This reflects a broader feeling that the pace of revolutionary breakthroughs may be slowing in favor of smaller, incremental updates. However, this view is not universal. OpenAI’s blog features a quote from Jeff Wang, CEO of Windsurf, who calls the update “the biggest leap for GPT models in agentic coding since GPT-5” and claims the version number “undersells the jump in intelligence” (Source: OpenAI Blog). This disparity shows that the perceived value of the update depends heavily on the specific use case.
The Entrepreneur’s Playbook: How to Extract Real Value
For an entrepreneur, the debate over version numbers is secondary to the practical question of ROI. To leverage GPT-5.2 effectively, a strategic approach is required.
Targeting ROI with Agentic Workflows
The highest potential for value lies in what OpenAI calls “agentic” workflows. These are not simple Q&A sessions but complex, multi-step processes that the AI can execute with some autonomy. The most compelling use cases involve integrating GPT-5.2 with other tools and data sources to automate professional tasks from end to end. A prime example comes from AJ Orbach, CEO of Triple Whale, who stated, “We collapsed a fragile, multi-agent system into a single mega-agent with 20+ tools. The best part is, it just works” (Source: OpenAI Blog). Entrepreneurs should look for similar opportunities in their own operations where a chain of manual, information-based tasks can be consolidated and automated.
Quantifying Time Savings
OpenAI provides a baseline for potential productivity gains, claiming that the average ChatGPT Enterprise user already saves 40-60 minutes per day, with heavy users saving over 10 hours a week (Source: OpenAI Blog). GPT-5.2 is designed to deepen this impact. To realize these savings, businesses should identify specific, time-consuming knowledge work—such as summarizing research, drafting sales presentations, or refactoring codebases—and systematically integrate the AI as an assistant to accelerate these processes.
Managing the 40% Cost Increase
The improved performance comes at a literal cost. API costs for the main gpt-5.2 The model has risen 40%, from $1.25 per million input tokens and $10 per million output tokens for GPT-5.1 to 1.75/14 for GPT-5.2 (Source: OpenAI Blog). This necessitates a tiered strategy for implementation. Businesses should use the faster, cheaper “Instant” model for routine tasks like simple translations or drafting emails. The more powerful and expensive “Thinking” model should be reserved for high-value, complex jobs where accuracy is paramount. For the most demanding jobs, OpenAI introduced a new top tier gpt-5.2-pro, designed for “difficult questions where a higher-quality answer is worth the wait.” This premium performance comes at a significantly higher price of $21 per million input tokens and $168 per million output tokens, reinforcing the need for careful, ROI-driven deployment (Source: OpenAI Blog).
Designing Better Workflows
To fully exploit the new capabilities, entrepreneurs should rethink existing workflows. The model’s improved long-context understanding makes it viable for tasks previously out of reach, such as analyzing a lengthy legal contract for key clauses or synthesizing findings from a dozen different market research reports into a single cohesive summary. Its superior tool-calling ability means it can more reliably interact with multiple internal systems—pulling data from a CRM, analyzing it, and then generating a formatted report—with less manual intervention and fewer errors along the way (Source: OpenAI Blog).
What’s Still Missing: Known Limitations and Ongoing Issues
Despite the advancements, GPT-5.2 is far from perfect. OpenAI is transparent about some limitations, while others are voiced loudly by its user base.
The Imperfection Clause
OpenAI includes a crucial disclaimer in its announcement: “Like all models, GPT‑5.2 Thinking is imperfect. For anything critical, double-check its answers” (Source: OpenAI Blog). This is not just legal boilerplate; it is a fundamental operating principle for any business using the technology. Human oversight remains non-negotiable for any task where errors have real-world consequences. The model is a powerful assistant, not an infallible oracle.
Ongoing Safety and Refusal Problems
The company acknowledges that it is still working on “known issues like over-refusals,” where the model declines to answer benign prompts due to overly cautious safety filters (Source: OpenAI Blog). This abstract problem has concrete consequences for users. For example, one user who writes dark fiction reported being constantly flagged for self-harm warnings: “I don’t need a wellness check because I’m writing about dark things or thoughts. It’s a way to get them out” (Source: r/ChatGPT). This highlights the ongoing challenge of balancing safety with utility. The detailed System Card discusses ongoing work related to safety and bias, confirming these are active and complex areas of research (Source: OpenAI System Card).
Persistent User Frustrations
Many of the core frustrations users have had with the platform are not resolved in this update. The Reddit discussions are filled with complaints about the strictness of the content filters, which can hinder creative writing and other legitimate use cases (Source: r/ChatGPT). Furthermore, the highly anticipated “adult mode” for less restrictive conversations has been pushed back to a tentative Q1 2026 release, disappointing a significant segment of the user base (Source: The Verge, r/ChatGPT).
Frequently Asked Questions (FAQs)
Q: Is ChatGPT 5.2 a major leap or a small improvement?
A: The sources portray it as a significant incremental improvement focused on professional and agentic tasks, not a revolutionary leap. While benchmarks show state-of-the-art performance in specific areas like coding and reasoning, the “5.2” designation and rapid release after 5.1 suggest an evolution of the existing platform (Source: OpenAI Blog, r/ChatGPT).
Q: What should entrepreneurs realistically expect from this version?
A: Entrepreneurs should expect a more reliable tool for complex, multi-step workflows like analyzing long reports, generating formatted spreadsheets from prompts, and debugging code. They should not expect a perfect, error-free assistant. The goal, as stated by OpenAI, is to “unlock even more economic value” by augmenting professional work, not fully replacing it (Source: The Verge, OpenAI Blog).
Q: Does 5.2 solve the accuracy problems people had with 5.0 and 5.1?
A: OpenAI officially claims it does, stating that “responses with errors were 30% less common” and presenting data that shows a lower rate of major factual errors (down to 5.8% from 8.8% for GPT-5.1). However, some user reports claim the opposite, suggesting that real-world performance may vary significantly by use case (Source: OpenAI Blog, OpenAI System Card, r/ChatGPT).
Q: Can it replace certain roles or just augment them?
A: The sources strongly indicate its purpose is augmentation. The GDPval benchmark, for instance, measures the model against “top industry professionals,” suggesting it can perform tasks at an expert level but within a framework of human oversight to save time and cost, rather than eliminating the professional’s role (Source: OpenAI Blog).
Q: How should I use it in my business to get the ROI the sources describe?
A: To see a return, focus on specific, structured knowledge work. Use it to automate the creation of first drafts for presentations and spreadsheets, assist developers in refactoring codebases, or synthesize information from multiple large documents into a single summary. The key is applying it to time-consuming professional tasks where it can accelerate human experts (Source: OpenAI Blog).
Final Thoughts: The Final Verdict for Your Business
Based on the available evidence, GPT-5.2 is measurably “better” in the specific professional and agentic capabilities that OpenAI targeted for improvement. The benchmark data shows clear gains in coding, reasoning, and accuracy that could translate into real productivity benefits for businesses that rely on knowledge work.
However, its value to your business is not guaranteed. It depends entirely on strategic implementation that plays to its strengths, careful management of the increased and tiered API costs, and a steadfast commitment to maintaining critical human oversight. The widespread user skepticism serves as a crucial reminder that benchmark performance does not always equate to flawless real-world utility.
The most pragmatic step for any entrepreneur is to move beyond the hype and conduct a focused pilot. Identify a single, high-friction, information-based workflow within your business – be it in marketing, operations, or product development – and test GPT-5.2’s impact on measurable outcomes like time saved, cost reduced, and quality improved. The true advantage lies not in chasing the latest version number, but in methodically integrating these powerful – but imperfect – tools to solve real business problems.
